How to Build a Local AI Economy for your nation - and why everyone is getting it wrong
All without spending billions of dollars upfront

Background: this is a written long form of the presentation i gave during the ASEAN Digital Minister’s Meeting. Slides are available here
AI is slowly becoming foundational infrastructure for the next era.
The real question is no longer whether AI will be adopted, but:
who controls it
how it is adopted
and who benefits from it economically
I get asked a version of this question very often:
How do we build a local AI ecosystem?
- For economic growth?
- For sovereign AI control, privacy and security?
However, there is a common mental model behind most of these discussions.
Which in my opinion, is wrong.
The wrong pipeline most people are assuming
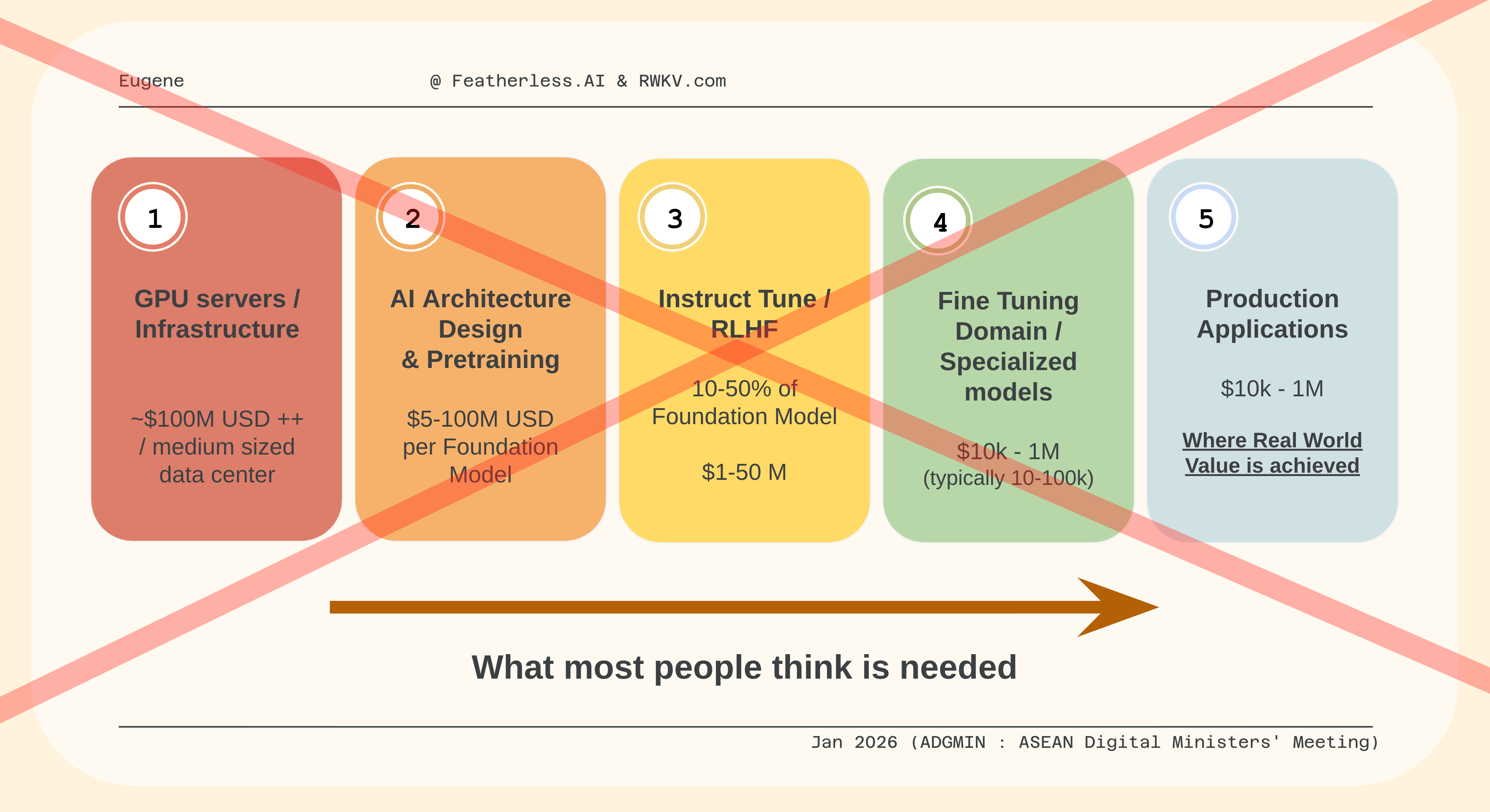
This is roughly the path taken by OpenAI and other frontier labs.
It is also:
extremely expensive
slow (takes years to build up talent and infrastructure)
optimized for research labs, not local ecosystems
And by the time applications are being built, with commercial value and economical impact. Years would have gone by.
Why this way of thinking fails in practice
The problem with this model, is not that it’s incorrect.
It’s that it assumes you must finish the earlier stages to do the later ones.
This assumption no longer holds. Open source AI has changed the economics.
For example, below - guess which response is from ChatGPT 5.2, and which is from an Open model downloadable today.

Today, strong pre-trained and instruction-tuned models already exist off the shelf. Many of them are competitive with frontier systems for most real-world tasks.
The main exception being on the “frontiers” of AI used in scientific research, and long horizon tasks. Most of which is not needed in most industries such as banking and customer servicing.
In that sense, others have already:
paid the cost of experimentation
absorbed the cost of failure
released their work publicly
You do not need to repeat that journey.
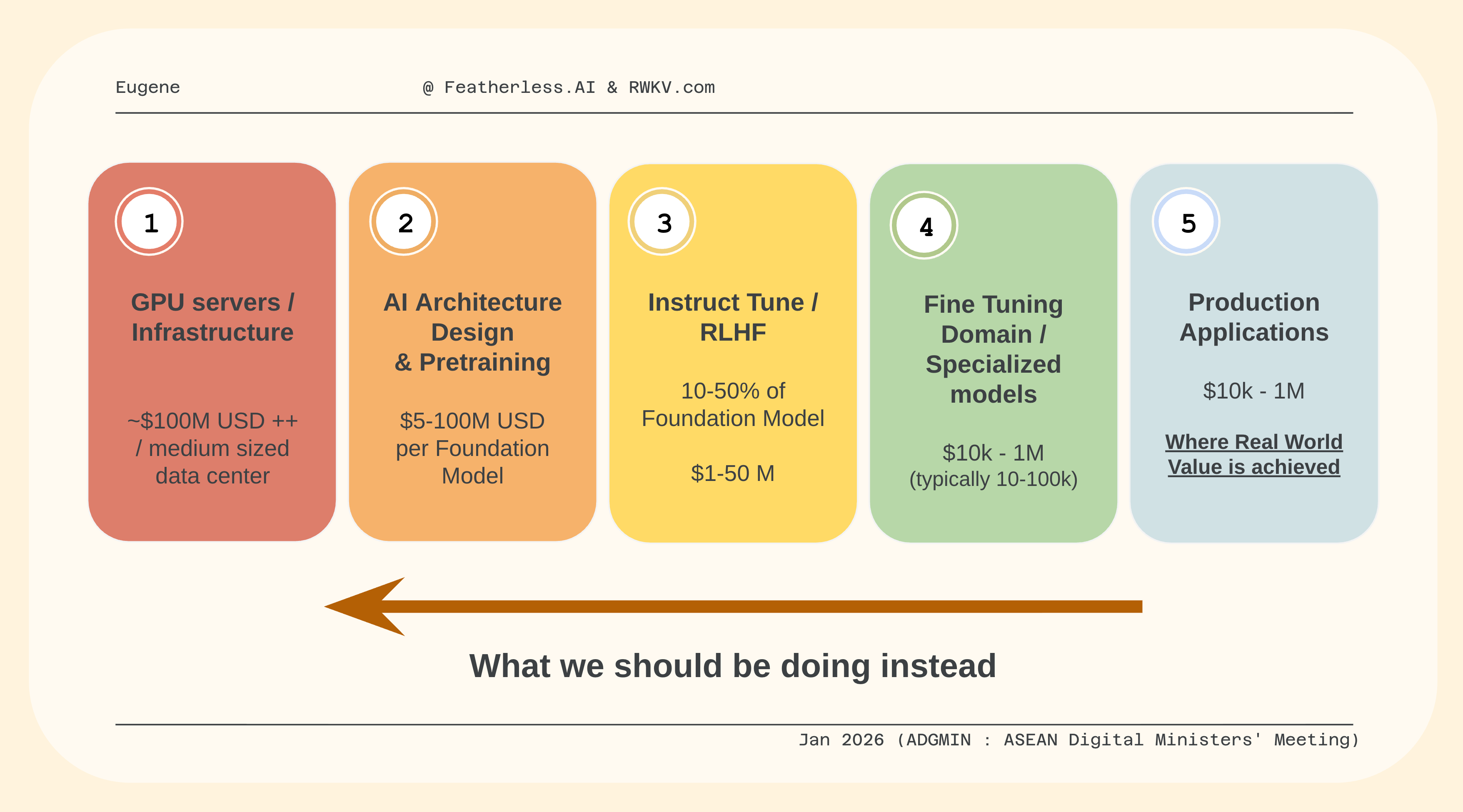
Start where the real commercial value is …
Specifically:
Applications with existing large models, using custom prompts with RAG systems, proving adoption
Before subsequently fine-tuning to expand use cases, language support,
and new domains to have tighter control and alignment
While we cite $10k-1M for these efforts, the later covers isolated larger projects and initiatives with large datasets. For the vast majority of projects we see, this trends towards the $10-100k cost.
That is cheap enough for:
universities
startups
small teams & grassroots efforts
In addition most of the goals for Sovereign AI is to maintain
Domestic use case & language support
Privacy & Security
Reliability & Control
All of these goals are achievable by fine-tuning existing major models instead of pre-training from scratch. And be flexibly deployed either in sensitive private datacenters (for secure govt use), or public cloud (for commercial usage).
Highlighting case studies : Who did not need 100’s of millions for impact
Case Study 1: Sunbird AI - Sunflower AI models
Sunbird AI released Sunflower, Uganda’s first homegrown multilingual AI model designed specifically for local languages. Outperforming Google’s and OpenAI systems in local languages use cases in 24 out of the 31 Ugandan languages.
Built by fine-tuning existing major open source models from ranging from 14 to 32 billion parameters. With models small enough to run on medium to high end notebooks.
With real-world use cases Sunbird AI is being used by : farmers for agricultural guidance in their native languages, educators can translate learning material for students, and healthcare workers can communicate more effectively with patients without language barriers.
Advancing digital inclusion, cultural preservation, and equitable access to technology across Uganda.
Case Study 2: Kissan AI - Dhenu Agriculture model
Kissan AI developed Dhenu (named after the divine bovine goddess), in inida, a language model trained for agricultural and farming use. In English and Hindi
Built by fine-tuning existing major open source models from ranging from 3 to 8 billion in parameters. Which are models that are small enough to run on mid-to-high end phones and tablets.
They allow the usage of AI, where internet connectivity is sparse or even non-existent. Helping farmers improve decision making and productivity.
Applications first, not pre-training or infrastructure first
By starting with application and/or finetuned models, we avoid a common failure mode I see is this:
“We will build a national model first, then later figure out how to use it.”
Which often burns through tens to hundreds of millions of dollars with little to show.
It allows you to predict and scale to what is needed downstream.
Allowing you to more accurately scale secure AI infrastructure for sensitive use.
While leaving the commercial AI infrastructure usage demand to be met by the public market and funding, while avoiding burdening the nations budget.
When applications are deployed on the ground, they create direct feedback:
whether better language support is needed
whether models need to be more specialized
whether inference costs are too high
and where infrastructure becomes the bottleneck
Achieving economical impact within months not years. While having the flexibility to move up the chain when demand for it grows.

More importantly:
Even if you pre-train it right, but do not fine-tune a model well and fail to deliver on no applications using it, you have failed — with little to no economical impact with the millions invested in.
The reality is, all ideas will carry risks, but starting from applications allows you to test economically multiple ideas at scale, quickly - at the price of a single pre-train model, or a major AI datacenter project.
Its also worth acknowledging: when it comes to new technology where one do not fully understand. Policy has a tendency on focusing on the familiar, infrastructure.
What about AI control and abuse?
For control and AI abuse prevention, these can be safeguarded through policies, that prosecute the misuse of AI. Essentially treating it like a dual use tool.
A mental model i have advised policy maker, is to write policies from the lens where there is access to large pools of outsourced low-cost labor. And apply it to both humans and AI usage.
For example:
Policies against the usage of large number of fake/paid personas, used for manipulation of public opinion and elections. Done through the usage of large pool of human labor and/or AI agents, pretending to be domestic residents.
Policies against the usage of false images and videos, for slandering and blackmailing. created through professional photoshop / video editing / AI image or video generation.
Policies against strengthening cross national prosecution against scams. Done through Human / AI call centers.
The unfortunate reality, as the AI model sizes required to achieve some of these abuse behaviour is shrinking to one that is runnable on “off-the-shelf” hardware like high-end laptops. Because these use cases do not need “large 500 Billion parameter models”
Centralizing into a sovereign AI model and infrastructure. Will not make these tools disappear.
Common push back: But how are we gonna compete with the bigger models?
Here is an industry secret: for specialized production application you do not have to.
You only need to get it to be reliable and good enough for the end-customer use case. Another factor is, when you run things commercially at scale, the bigger the model gets, the more expensive it becomes.
This is reflected in our traffic data usage as well
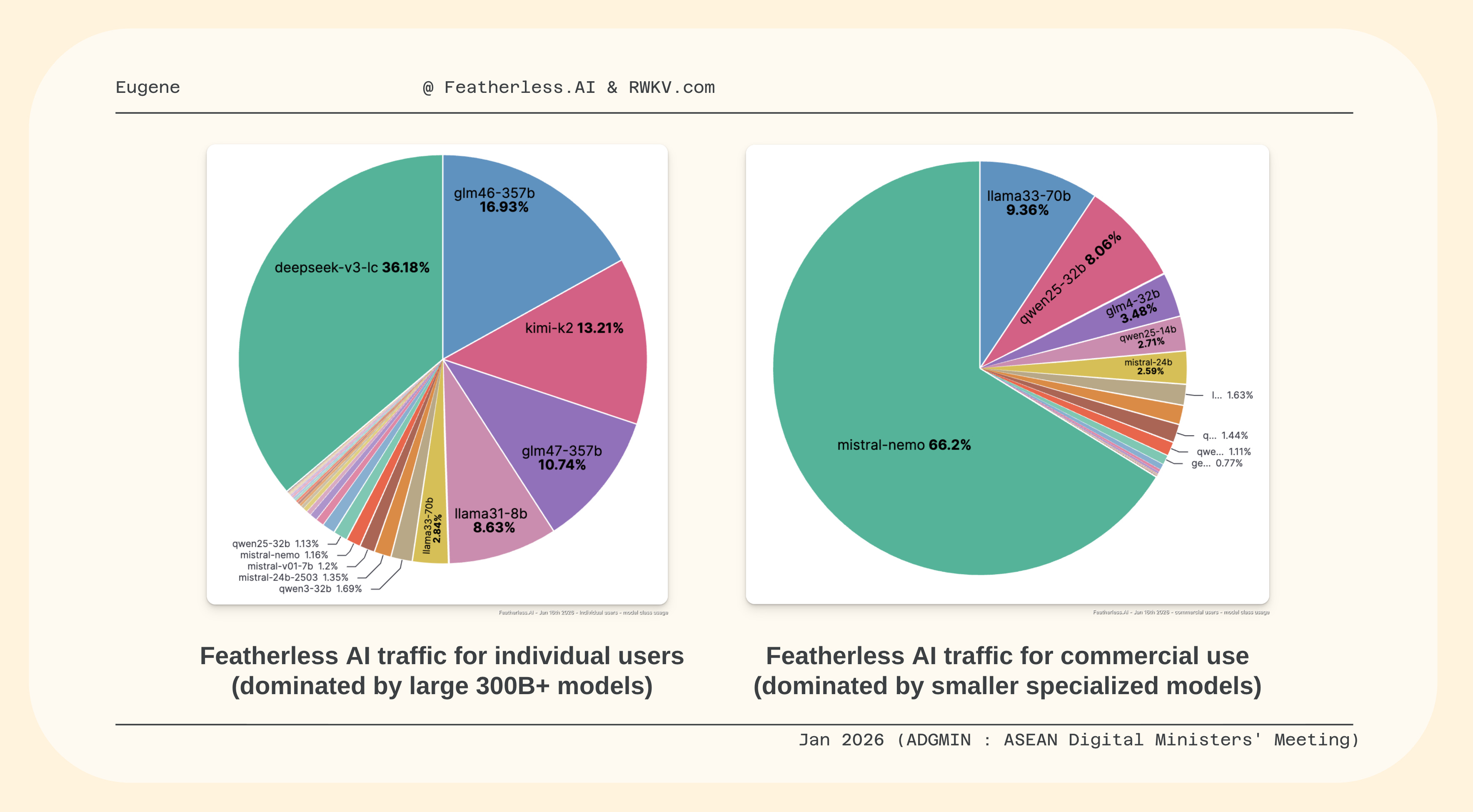
Because individual users, tend to use AI models across a large spectrum of use cases, individuals tend to use more versatile models (they can pick any of the models on our platform at the same price), where larger models dominate their usage.
However for commercial scale, where the smaller models means “more tokens and requests” for the same dollar. We see heavy reliance of 12B to 32B models in the use cases tuned for them.
You do not need an expensive Einstein model to do everyday college task at scale. Especially when you can get more consistent and even better results, with efficient trained specialized model, for your domain.
We expect this trend of larger off the shelf models being used for exploration, and experimentation to maintain. As it balances the need for fast experimentation and go-to-market. And efficient cost management of AI at scale
One more thing: Pre-trained models are becoming a commodity
Two years ago, a strong open-source model was released every few months.
Today: releases happen monthly, sometimes weekly with the gap closing. All while running on smaller hardware, and outperforming the best close-source models one-to-two years ago.
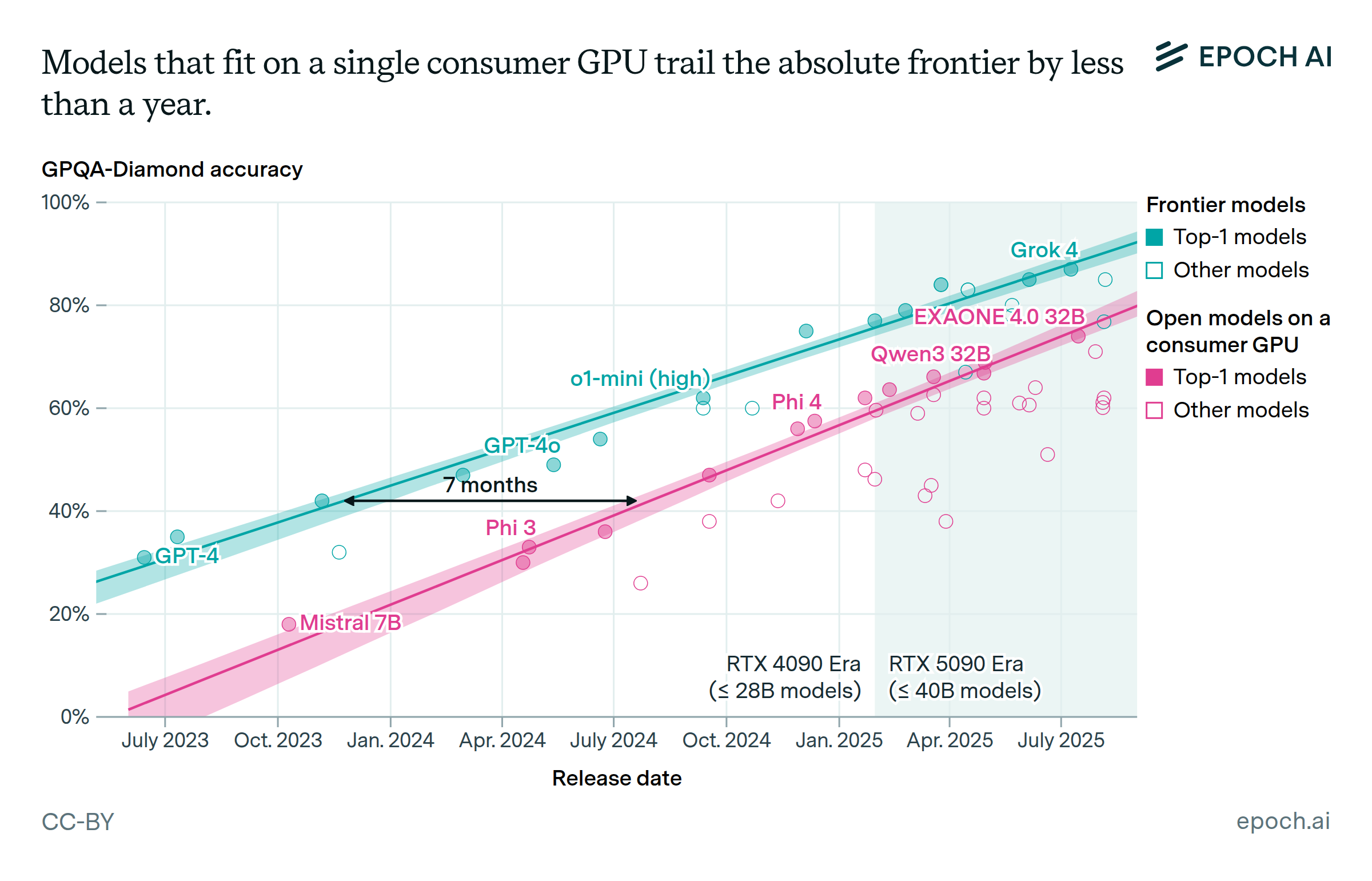
While major closed source commercial models are still in the lead.
The gap has been shrinking rapidly in the open model space
While being smaller and cheaper to run. Today the best open models that can run on a $10k desktop PC can give similar or better results to the larger GPT4 models which required $300k servers in data centers to run.
The pace is so fast that several times many new pre-trained models are obsolete within days. Benefit from this trend by building on pre-trained models, instead of against it.
Few industries exists, where the best commercial solution, which costed 100’s of millions, is made freely available consistently in under 2 years.
Clarifying question: If some of these models can be deployed on cheaper hardware, why is there still strong demand for larger servers?
There are two major factors for AI, the model size, and compute.
Larger model sizes, pushes the minimum hardware requirements for memory chips in the AI system. For example, a high-end Apple PC with 256 GB vram (or 256 Billion Bytes), can run a 120 Billion parameter AI model. But not the larger 1.7 Trillion parameter model, GPT 4 alleged size. Which would requires higher end servers with 2 TB vram (or 2048 Trillion Bytes)
Another major factor is compute. While you can run on a mac studio a 120B model for one user at a time. will struggle for anything more then that. It lacks the compute compared to a high end AI GPU server, which can run for over a 100 users in parallel the same model, at faster speeds.
At scale, when serving thousands or millions of users, these higher end machines are essential. But for business who do not need such volume, open source models help them right size to their needs.
Answer to “guess the model”

About the author
Eugene Cheah is the founder of Featherless AI and co-lead of the RWKV open-source AI project, the first AI project under the Linux Foundation. He works on AI inference, efficient architectures, and building practical AI systems used in production globally.
With our background in Open Source AI - We are interested in collaborating in scaling open source AI models to meet your nations or Soverign AI needs, with your local industries. Feel free to reach out to eugene @ featherless.ai